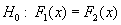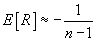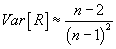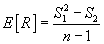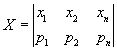
(10.1)
To understand processes that intervene in the water cycle and to study their spatial and temporal variations, a database is essential. Field observations are very important for climatic statistics, for planning and management of water resources.
Measurements are recorded using a wide range of methods, from the simple writing of a number by a single observer to the invisible marking of electronic impulses on a magnetic tape. Although the most advanced techniques are used in developed countries, many nations of the third world employ only direct manual methods [Shaw, 1988].
Data Archives and Publication
Old meteorological measurements were tabulated on specially designed forms and are stored in boxes occupying considerable shelf space at headquarters. These are historical data valuable for students or hydrologists who study past extreme rainfalls. Instead of abstracting the figures manually the potential user must be able to define precisely his requirements from a system embodied in a computer software. Nowadays computer programs are written to abstract information.
Considerable attention is now given to the present need for data. The technique used to solve problems in ungauged catchments, by using information from neighbouring catchments, continues to be investigated [Shaw, 1988]. Although data publication is highly desirable, the time taken for a yearbook to appear means that data are only of historic value, useful for assessing past conditions. Operationally hydrometric data are disseminated to users for the customer's own analysis. The USA has an excellent record of data publication; its series of Water Supply Papers being well known at international levels.
The Hydrological and Geological National Service publishes the Switzerland Hydrologic yearbooks. The Natural Environment Research Council of U.K. publishes yearbooks entitled Hydrological Data. The yearbooks regroup the following results:
Some of these values can be presented in an isohyets map.
The measurement results can be written as a random variable:
|
|
(10.1)
|
For a random variable the following characteristics can be calculated [Musy, 2001]:
- median value
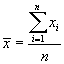 |
(10.2)
|
- average value
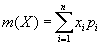 |
(10.3)
|
- average deviation
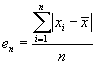 |
(10.4)
|
- dispersion
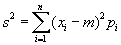 |
(10.5)
|
- square average deviation
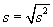 |
(10.6)
|
- impulses of superior order
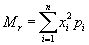 |
(10.7)
|
- coefficient of variations
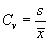 |
(10.8)
|
- centred impulses
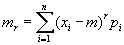 |
(10.9)
|
- coefficient of asymmetry
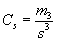 |
(10.10)
|
The data are received in specialized offices by:
The value of rainfall data depends on the instrument, its installation, its site characteristics, and its operation by an observer. Before publishing the data it is necessary to verify missing values, correct errors, etc. This can be done starting from the original documents (filed formularies, diagrams - which constitute archives) that are accessible only to specialized personnel.
Archives are then transformed into working files to allow data visualization and verification of the data precision and quality tests. The files are then operational and can be published and distributed to users [Musy, 2001]. The hydrometric data gathering agencies are national or local government authorities, and it is their duty to publish the data and make them available to the public.
To check the daily rainfall at a station neighbouring stations data will be used through interpolation. Suspect values are discarded and then each of the daily totals is converted to a percentage of the relevant station's annual average rainfall and the interpolated percentage rainfall (R) for the testing station is given by the following relation [Shaw, 1988]:
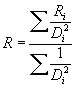 |
(10.11)
|
| where: | ||
| Ri | rainfall percentage of annual average at station i | |
| Di | distance between station i and control station (km) | |
The estimated value from the interpolated percentage will then be compared with the recorded value. The difference (DIFF) is considered insignificant and the record acceptable if DIFF < or = 2.5 mm and DIFF < or = 2 x error in estimation.
This checking procedure corrects automatically:
For each river flow station the expected response of the catchment to rainfall inputs depends on the catchment's characteristics that can be assessed, and thus a limit to the difference between consecutive stage readings can be fixed.
The daily mean discharge (m3s-1), representing the flow volumes in a day (m3) averaged over the number of seconds, is the final product of the data processing program. They should be checked every month. Discrepancies may be found when the following checking are made:
A quality-control computer routine is designed to deal with known conditions and events. It requires different structure depending on countries and climates.
There are several types of errors that can occur; on a first inspection, some of these may be identified and corrected at once, some are noted and marked, and others may remain undetected. They are:
1. "In situ"
2. Statistical investigations based on specific hypotheses. Hypotheses for a statistical analysis are:
Statistical tests
The following categories are of statistical tests:
1. Tests subsequent to their mathematic properties. In most cases, these tests are based on the normal law and assume the existence of a reference random variable X. The question is whether results are valid if X is not normal: if results are valid, the test is "robust". This means that the test remains almost insensitive to certain modifications of the model.
2. Tests subsequent to their object are classified in four categories:
If two samples are given, of n1 and n2 size, can it be admitted that these samples were part of the same population, but independent between them ?
Mathematically, the problem can be expressed as following: it can be observed on the first sample the realization of a random variable X1 and the repartition function F1(x), and on the second sample the realization of a random variable X2 and the repartition function F2(x).
It can be tested:
|
if |
|
if
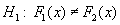 |
The comparison of a sample characteristic values with a reference value means verifying whether the characteristic can be admitted equally to the reference value. For example H0 : μ = μ0 where μ0 is the reference value, and μ is the unknown value.
Verifies whether a given sample is part of a certain population.
Verifies whether a bond exists between the chronological data of an observation series. Anderson has studied the distribution of the autocorrelation coefficient for a normal population. In this case, the autocorrelation coefficient can be calculated for n-values pairs (x1, x2), (x2, x3), …, (xn-1, xn), and (xn, x1). For a series n, Anderson limited the values at 75. The autocorrelation coefficient, after a normal law will be [Musy, 2001]:
|
|
(10.12)
|
After Anderson, Wald and Wolhowitz developed a non-parameters test of the autocorrelation coefficient, calculated by means of the following relation:
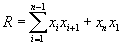 |
(10.13)
|
|
|
(10.14)
|
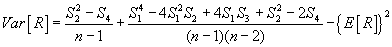 |
(10.15)
|
with:
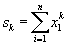 |
(10.16)
|
Autocorrelation discrepancies kρk of a stationary temporal series is defined by:
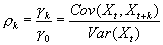 |
(10.17)
|
Autocovariance 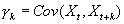 is estimated
through a n observation series x1, x2,
..., xn:
is estimated
through a n observation series x1, x2,
..., xn:
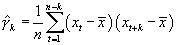 |
(10.18)
|
3. Tests subsequent to the nature of information. In hydrology there are different situations depending on particular hydrological situations. Sometimes it is necessary to control just one type of data (rainfall, temperature, and evaporation) for local flow or regional flow, and sometimes it is necessary to control different types of data (rainfall-discharge, temperature-wind velocity) for local and regional flow. (More details can be found in Musy, "e-drology", 2001)
Musy, A. 1998. Hydrologie appliquée, Cours polycopié d'hydrologie générale, Lausanne, Suisse.
Musy, A. 2001. e-drologie. Ecole Polytechnique Fédérale, Lausanne, Suisse.
Shaw, E. M. 1984. Hydrology in practice, Second edition. T.J. Press Ltd., Cornwall, United Kingdom.
Vladimirescu, I. 1978. Hidrologie. Ed. Didactica si Pedagogica, Bucuresti, Romania.