Natural systems are very complicated and high-organized systems. Water quality models try to simulate changes in the pollutants concentration as they move through the environment. A pollutant entering the environment may increase or decrease its concentration due to a large variety of mechanisms. The fate of pollutants is the resultant of interactions between mass transfer and kinetic processes. All these changes are the subject of water quality modelling.
Modelling is a continuous process of developing models in times parallel with the increase of the available information and knowledge about the simulation system, which more and more adequate to describe the real process. The focus here is the user to receive the basic knowledge about water quality modelling by means of introducting the purpose, type, structure and application of the water quality models.
Mathematical models are a means for governmental institutions to gain the best social and economic solutions of water problems and play very important role for the integrated watershed management. A model is a system of equations, relationships and observed monitoring data, created for description of the natural system, for demonstration and checking of its behaviour under different conditions in time and in suitable type with significant economy of money and time.
The use of mathematical models is the shortest way to:
The purpose of modelling should be clear and well defined to achieve maximum simplicity consistent with the required degree of accuracy and detail in the process of description of the natural system. In general, the purpose of modelling falls into one of the following categories (Zheng & Bennett, 1995):
The fundamental principles for water quantity and quality modelling are:
The key elements for creation of the suitable water quality models are related with the good knowledge about a change in state of a system, presented with the difference in properties between the final and the beginning state. The process of model building is an iterative process, which starts with expression of a working hypothesis, typically based on a priori knowledge about the system in the form of mathematical model. An experiment is like a window through which the nature is viewed. Our view is never perfect. Interaction between experimental data collection and data analysis provides the opportunity for improving precision by shifting emphasis to different variables, making repeated observations, and adjusting experimental conditions. The assessment of water quality is always related with the determination of water flow characteristics. It is not possible to assess water quality without evaluation of the water quantity. That is why the water quality modelling includes as a main part the water quantity modelling, which gives the answer how water movement affects the concentration of the dissolved and suspended constrains.
The creation of a water quality model involves the following two stages:
The main steps of model building may be explained as follows (James, 1996):
The instantaneous equations for fluid flow and pollutant transport are:
The used solution techniques for solving the basic equations are:
The simplifications are related to the resolution of water quality processes in time and space, and the numerical techniques used to solve the governing equations.
All simulations are subject to uncertainty. Hydraulic and transport parameters and boundary conditions are never known in sufficient detail and the existing distributions of the pollutants are often poorly understood.
Uncertainty in the results may be classified into two general categories:
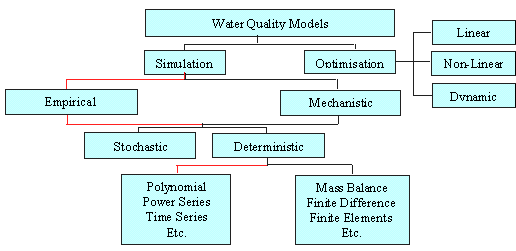
The field of the water quality models is very large and includes different kind of models in dependence of the level of the input and output information, the complexity of the modelled events, the modelled water body, the used mathematical methods, the type of the basic equations, the aim of the modelling, the structure of the modelling system, the scale of interest in steady-state or non-steady state conditions and others. Many different types of water quality models are available so it is not possible to give a simple classification (Figure 9.1).
The optimization models are a group of mathematical techniques used to obtain the least costly solution to some allocation situation. The simulation models describe all models representing water quality changes in some mathematical form including all types of mechanistic models in which the processes are deterministically represented, and also statistical models.
Mechanistic water quality models are models that by means of mathematical tools express the mechanisms of the process that cause changes on water quality and lead to establish the relationship "cause-and-effect". The mechanistic models have some advantages:
Figure 9.1 Classifications of Water Quality Models
Empirical models are "black-box" models. Purely empirical models, such as many statistical models, allow description of the fixed relationships between input data and output results with a minimum of understanding about how the system works. Statistical models estimate the parameters through statistical analysis and then check the adequacy of the model. One of the principal restrictions of the empirical models is that they cannot be implemented to other close systems or for data out of the range used for creation of the model (J. Martin, 1999).
The common tendency is the model to be more fundamental and less empirical. From the practical point of view the water quality management models will have empirical character in future.
Deterministic models have a fixed relationship between input data and output results, which may be empirical or mechanistic.
Stochastic models contain some random elements. They are divided into: steady-state Monte-Carlo simulation models, using a mass balance model, which generate an output result with varying input conditions in the form of a frequency distribution of the pollutant concentration, and dynamic time series simulation models, using a dynamic finite difference model.
Modelling framework of water quality in rivers includes two basic steps:
Estuaries are a distinct part of the river system: the transition zone between rivers and saline habitats. Water quality models include:
Mainly by function of pollutants the water quality models are divided into two broad groups:
Usually these two models work together, included in one common decision making system. It evaluates the water quality in every reach of the river, resultant from point and non-point sources of pollution together with integration of the self-purification capability of the stream flow and all the physical, chemical and biological processes simulations.
Monitoring of aquatic environments generally produces data in the form of repeated observations of some parameters at various sampling points. The data are divided into three types:
The analysis of the monitoring data has to be made. First the data are plotted on a time basis (Figure 9.2). Visual inspection is an essential preliminary step to the more detailed analysis related with the assessment of the common trend of changing and the notation of the measurements, declined from the trend.
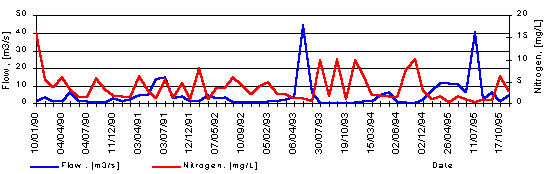
Figure 9.2 Analysis of observed data
For better understanding some examples are presented below with some characteristics of a special water quality assessment system REKA (River Environmental Knowledge and Assessment), developed for the Yantra river basin in Bulgaria to evaluate non-point and point sources of pollution in a media of Geographical Information Systems (GIS). REKA has two sub-components: BISTRA (Basin Impacts of Simulated Transport from Rural Areas) and VODA (Validation and Optimization for Decision Analysis). The system goal was to create an approach to assess the water quality in various river reaches in dependence of future climate variability and socio-economic changes.
Application of the REKA model requires the availability of a comprehensive, well-structured database for assessment of the water quality of a given watershed and river reach. All these spatial data are presented as ArcView map layers giving the geographical position of the objects. The numerical data related with these objects are structured in attribute tables attached to the layers. Some required input layers are presented for Yantra river basin, in Bulgaria.
The total Yantra watershed as well as the tributary subbasins, the latter arranged for running the non-point source pollution model, are represented in Figure 9.3.
Figure 9.3 subbasins and river set
The Digital Elevation Model (DEM) supplies very important information about the slopes of the terrain and the river reaches (Figure 9.4).
Figure 9.4 DEM model
Flow monitoring data are needed for calibration of the stream flow results. They are related to the gauge stations, defined geographically as a separate gauge station layer. The daily rainfall and temperature data are presented for every meteorological station.
The land use data were supplied from digitized land use maps entered in GIS layers. Typically, land use maps are created by specialized services using topographic base maps and field studies. When available, satellite images are useful for improving land use maps (Figure 9.5).
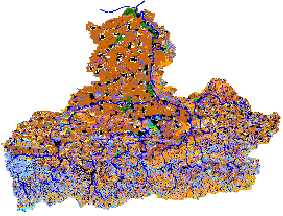
Figure 9.5 Land use map
BISTRA requires a large number of soil characteristics specified by soil types. Figure 9.6 represents the Yantra River basin soil map.
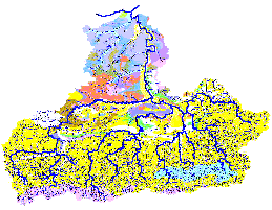
Figure 9.6 Soil map
The demographic data include settlements and the administrative division of the watershed. The settlements are organized in 26 municipalities and in 6 counties and classified by analysis of the Land satellite imagery in 3 types:
They are gathered for every water quality monitoring points for calibration and validation of the BISTRA and VODA models.
BISTRA was developed for estimation of the non-point pollution in the Yantra River Basin on the basis of the GWLF model/GISArcView Interface. BISTRA assesses stream flow, nutrients and sediments in the 75 regions of the basin (Figure 9.7), for every outlet of the subbasins. The input information includes 10 layers and related attribute tables and some specific parameters, for which values were evaluated during the calibration procedure.
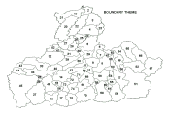
Figure 9.7 subbasins watersheds
The BISTRA model allows:
The application of the BISTRA model to the Yantra River basin includes:
Choice of subbasins was based on the following important requirements:
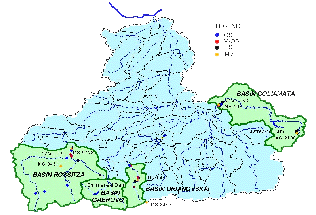
Figure 9.8 Calibration subbasins
Six subbasins were designated as the representative for the BISTRA calibration (Figure 9.8).
The calibration procedure includes: hydrologic calibration of the monthly stream flow and nutrients and sediments calibration.
As a result of the calibration procedure for every subbasin the final graphs (Figure 9.9 and Figure 9.10) for the monthly stream flow and monthly nutrient and sediment loads are received.
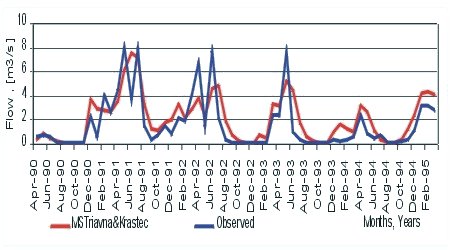
Figure 9.9 Comparison between observed and simulated monthly
flow
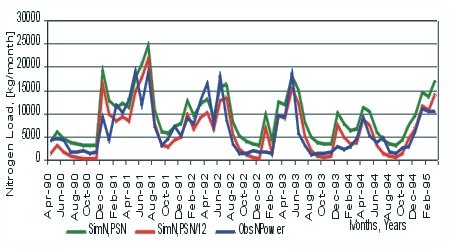
Figure 9.10 Comparison between observed and simulated monthly nitrogen load in the river
The calibration procedure is followed by the presentation of the statistical assessments and comparison between simulated and observed flow and simulated and observed nutrient loads and sediments.
To validate the BISTRA model it is necessary to have the corresponding observed values. In reality there are monthly data for the validation of flow only for some points of the Yantra river. Figure 9.11 shows the situation of all the basins, used for BISTRA model validation.
 |
 |
 |
 |
Figure 9.11. Validation subbasins
The comparison between simulated and observed flow for Yantra mouth is presented in Figure 9.12.
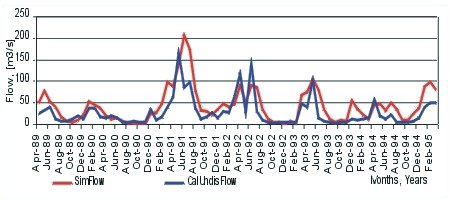
Figure 9.12 Comparison between simulated and observed flow for Yantra mouth
The output for every subbasin are: monthly precipitation, evapotranspiration, groundwater, runoff, stream flow, erosion, sediment, dissolved nitrogen and phosphorus and total nitrogen and phosphorus loads. The output values are divided in to two parts: from agricultural lands and from other lands, using the empirical dependencies and entered into proper order in input for VODA Excel file.
VODA is a substantial revision of the STREAMPLAN model of the International Institute of Applied Systems Analysis, developed exclusively for the basin of the Yantra River in Bulgaria. It is based on a ten years' period (1986-1995) database. REKA delivers loadings and water volume data to VODA by stream reach. VODA then computes flows and pollutant concentration and loads by reaches. The hydraulic model that underpins the VODA software assumes steady and uniform flow hydraulics in each river reach. In the water-quality model, the rate of concentration of water quality variables is assumed to be a linear function of the concentration of the water quality constituents. The socio-economic model has a pre-optimization screening procedure (for efficient operation) and an optimization step that is oriented toward in-river oxygen quantity as an indicator of river water quality.
VODA can be used to generate a scenario based on current conditions or to simulate the water quality impacts of proposed treatment facilities or discharge regulations. Alternatively, VODA can calculate financially optimal strategies to achieve water quality improvement goals or to meet specified standards for all or some of the stream reaches. Decision choices include alternative allocations of reservoir water for dilution; temporary or permanent closing of polluting entities; and capital and operational costs of pollution pre-treatment and treatment. VODA also has for input alternative weather conditions, based on the validation period or a typical wet, average, or dry year. It is also possible to include temperature and precipitation change scenarios derived from global climate change models. Typically, simulations will be framed in terms of low-flow months during relatively dry years. The numerical results of VODA's simulation and optimization are then passed back to ArcView for presentation. The results can be viewed as Excel charts and tables or as GIS-layers - ArcView shapes (Figure 9.13 and Figure 9.14).
Figure 9.13 Worst (highest) BOD - Dec/92
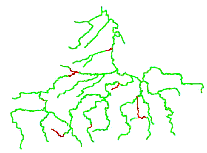
Figure 9.14 Best (lowest) BOD - Dec/92
In summary, it has to be mentioned that the water quality models have shown that they are the most convenient and powerful operational tools that allow to precise the water quality management policies. Nevertheless, they are always necessary to perform many various simulations of different pollutants for a given basin, to create many different scenarios for every sensitive river reach and to present the emission reduction sensitive area, which can vary with the periods of investigation and also with the meteorological weather conditions.
Bibliography
James, A. 1993. An Introduction to Water Quality Modelling, 2nd edition. John Wiley & Sons Ltd, New York.
Martin, J., and McCutcheon. 1999. Hydrodynamics and Transport for Water Quality modelling. CRC Press, New York.
Zheng, C., and B. Gordon. 1995. Applied Contaminant Transport Modelling. Van Nostrand Reinhold, New York.